Quando nel novembre 2014 inviai in omaggio una copia del Manuale di Crittografia di mio nonno Luigi Sacco al prof. Consolato (Tito) Pellegrino di Modena, un amico che conoscevo da molti anni, non mi aspettavo certo che da questo omaggio sarebbe nata un'appassionante sfida crittologica, quella di decrittare l'ultimo poema di Pietro Giannone. Per questo Tito mi inviò il PDF di un articolo del 1961 di Alfonso Morselli che presentava alcune pagine criptate del manoscritto e ne raccontava la storia.
Dopo aver letto l'articolo del Morselli, scritto nel 1961, iniziai a studiare a pieno il cifrato il 27 dicembre; ottanta pagine di testo scritto con simboli vari, si riconoscevano le nove cifre da 1 a 9, molte lettere latine minuscole ed anche maiuscole, e poi simboli geometrici di ogni sorta, croci, angoli, quadrati, rettangoli con varie appendici e puntini dentro, sopra, sotto, a lato. Un primo attento esame metteva in luce diversi elementi interessanti:
Nel suo insieme il cifrato ricordava certi messaggi cifrati della diplomazia veneziana del periodo rinascimentale, per esempio un dispaccio del 1554 riportato sul libro del Pasini.
Insomma la decrittazione, considerata anche l'ampia mole del manoscritto, non appariva un'impresa impossibile.
Il primo tentativo di attacco fu di tipo statistico; purtroppo il fatto di essere scritto a mano con calligrafia ottocentesca rendeva il compito di fare una statistica dei simboli molto problematico; in sostanza dovevo procedere a mano riportando i totali in un foglio di calcolo dove andavo raccogliendo i vari simboli incontrati nel testo; in contemporanea a Modena Tito realizzava una ampia statistica sul testo de "L'esule" l'opera più nota di Pietro Giannone, che ritenevamo potesse avere una struttura simile a quella del poema cifrato; in realtà solo una parte de "L'esule" era in ottave.
Un aspetto evidente della statistica condotta sul testo cifrato era il numero elevato, almeno un centinaio, di simboli diversi e la distribuzione di frequenze piuttosto uniforme; una frequenza piuttosto elevata era quella delle cifre da 1 a 9; questo suggeriva la congettura che si trattasse di un cifrario misto monoalfabetico, e per digrammi, trigrammi e forse anche parole intere (repertorio); le cifre da 1 a 9 erano buone candidate come cifre monoalfabetiche di vocali o consonanti frequenti.
L'unico risultato certo del confronto statistico fu che il simbolo ~ (ondina) era sicuramente una cifra di e la lettera statisticamente più comune in italiano e in quasi tutte le lingue europee; aveva infatti una frequenza elevata, compariva molto spesso a inizio verso (come ne "L'esule") e compariva anche molto spesso isolato (congiunzione e). Inoltre la cifra 1 compariva spesso isolata, cosa che suggeriva potesse essere la lettera a; un simbolo che sembrava una C corsiva maiuscola era molto frequente a inizio verso, e poteva essere L; le statistiche di Tito però suggerivano piuttosto una C. Ma questo era tutto quello che si riusciva a congetturare dalle statistiche.
Un altro aspetto evidente è che la lunghezza media dei versi era sui 20 caratteri, mentre quella degli endecasillabi è in media di 30 caratteri; una ulteriore conferma che il cifrario doveva essere almeno in parte formato di digrammi e trigrammi; un semplice calcolo algebrico poi dava un'indicazione più precisa.
Chiamiamo c il numero di caratteri monoalfabetici, d il numero di digrammi, t il numero di trigrammi per verso; allora le due informazioni di sopra si traducono in queste due equazioni:
$ \begin{cases} c+d+t=20 \\ c+2d+3t = 30 \end{cases} $
Moltiplicando la prima per 2 e sottraendo la seconda si ha:
$ \begin{cases} 2c+2d+2t = 40 \\ c+2d+3t = 30 \end{cases} $
$ c-t = 10 $ → $ c = 10 +t$
cosa che ci dà un'informazione importante: essendo $ t \ge 0 $ il numero medio di caratteri monoalfabetici per riga deve essere maggiore o uguale a 10; questo vuol dire che Giannone aveva commesso uno degli errori più comuni quando si usano questi cifrati misti: aveva usato troppo il cifrario più semplice e facile da ricordare, il monoalfabetico appunto.
Questa situazione mi ricordò un famoso episodio della Grande Guerra quando Luigi Sacco riuscì a forzare un cifrario austriaco sfruttando proprio un simile errore: quello dei radiogrammi di Conegliano.
A questo punto la strada da seguire era chiara: cercare una sequenza di caratteri(*), preferibilmente formati solo di numeri e lettere alfabetiche che erano sospettate come cifre monoalfabetiche, che contenesse qualche ripetizione; per facilitarmi il compito realizzai un piccolo programma in linguaggio PhP che permetteva di trovare in un testo sequenze ripetute, per esempio due caratteri seguiti dagli stessi due caratteri eventualmente intervallati da un carattere, come in "POPOLI" dove c'è un PO ripetuto due volte ecc.ecc. Come testo usai parti de L'esule in particolare quelle con ottave. Il programma era in grado di digerire anche 20000 caratteri alla volta.
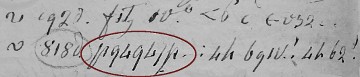
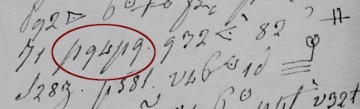 Iniziai questa caccia a gennaio; due sequenze attirarono la mia attenzione: p94p9 dove c'è il gruppo p9 che si ripete a distanza di un carattere e p94947p dove c'è il gruppo 94 che si ripete consecutivamente; varie ipotesi su queste sequenze si rivelarono sterili nel senso che applicate in altre parti del manoscritto davano risultati insensati; tentativo fallito.
Iniziai questa caccia a gennaio; due sequenze attirarono la mia attenzione: p94p9 dove c'è il gruppo p9 che si ripete a distanza di un carattere e p94947p dove c'è il gruppo 94 che si ripete consecutivamente; varie ipotesi su queste sequenze si rivelarono sterili nel senso che applicate in altre parti del manoscritto davano risultati insensati; tentativo fallito.
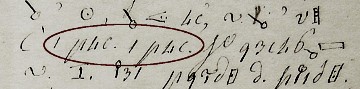 E il 7 gennaio pomeriggio, scorrendo il testo, alla pagina 3 del manoscritto una terza sequenza salta agli occhi: 1 p4c. 1 p4c.; questa è veramente interessante, un intero gruppo ripetuto; prima ancora di usare lo strumento software, come un lampo viene in mente la frase a poco a poco; provo a cercare con il programma, e l'unica sequenza di questo tipo che salta fuori da L'Esule è ancora quella: A POCO A POCO; mi precipito a fare la stessa sostituzione nelle due sequenze precedenti, ci vuol poco a trovare che p94p9 = PROPR, p94947p = PROROMP;(*) ed ecco che i pezzi del puzzle cominciano ad andare al loro posto. Ormai appare chiaro che ho aperto una breccia nel codice di Giannone.
E il 7 gennaio pomeriggio, scorrendo il testo, alla pagina 3 del manoscritto una terza sequenza salta agli occhi: 1 p4c. 1 p4c.; questa è veramente interessante, un intero gruppo ripetuto; prima ancora di usare lo strumento software, come un lampo viene in mente la frase a poco a poco; provo a cercare con il programma, e l'unica sequenza di questo tipo che salta fuori da L'Esule è ancora quella: A POCO A POCO; mi precipito a fare la stessa sostituzione nelle due sequenze precedenti, ci vuol poco a trovare che p94p9 = PROPR, p94947p = PROROMP;(*) ed ecco che i pezzi del puzzle cominciano ad andare al loro posto. Ormai appare chiaro che ho aperto una breccia nel codice di Giannone.
Quell' A POCO A POCO è stato qui, fatte le debite proporzioni, l'esatto equivalente del RADIO STATION che aveva permesso a Luigi Sacco di forzare il cifrario austriaco nel 1918. In queste parole Giannone aveva fatto lo stesso errore dell'ignoto cifratore austriaco, dimenticando simboli digrafici e trigrafici, e tornando al monoalfabetico. Un bell'aiuto arrivato dagli ... antenati.
Non resta che una cosa da fare d'urgenza: inviare una mail a Tito per informarlo dell'avvenuta rottura del codice anche per risparmiargli ulteriori ricerche statistiche che a questo punto non hanno più alcuna utilità; la mail porta come titolo "FERMA TUTTO!"
 Da questo momento in poi la decrittazione e la ricostruzione del codice, compresa la ricostruzione dei simboli digrafici e trigrafici e del repertorio, non presentano grosse difficoltà. A destra la prima coppia di endecasillabi ricostruita integralmente nei giorni successivi; in questi due versi emergono già i primi simboli digrafici e trigrafici: la T maiuscola sta per an il simbolo < per que ecc.ecc.
Da questo momento in poi la decrittazione e la ricostruzione del codice, compresa la ricostruzione dei simboli digrafici e trigrafici e del repertorio, non presentano grosse difficoltà. A destra la prima coppia di endecasillabi ricostruita integralmente nei giorni successivi; in questi due versi emergono già i primi simboli digrafici e trigrafici: la T maiuscola sta per an il simbolo < per que ecc.ecc.
Già da questi endecasillabi si intuisce quello che poi viene via via confermato; il contenuto del poema è ben diverso da quella storia della Modena sotterranea che Giannone aveva lasciato credere ad amici e familiari; si tratta di letteratura erotica sul genere del Decameron di Boccaccio con un linguaggio molto esplicito che ricorda quello dei sonetti lussuriosi di Pietro Aretino. E forse voleva essere veramente una storia della Modena sotterranea, ma in un altro senso!
Emerge anche che Giannone aveva introdotto molte varianti nel codice, in corso d'opera; cosa utile per ricostruire l'ordine corretto delle pagine; la rilegatura del manoscritto infatti non è di Giannone, ma di Silingardi, l'amico che ne ereditò le carte e che tentò inutilmente di decrittarle, prima di lasciare il tutto come lascito al Museo del Risorgimento.
Prossimamente maggiori dettagli sulla decrittazione del poema e una descrizione strutturata del codice.